



I'm happy that with Qt 5.8.0 we'll have Qt Speech added as a new tech preview module. It took a while to get it in shape since the poor thing sometimes did not get the attention it deserved. We had trouble with some Android builds before that backend received proper care. Luckily there's always the great Qt community to help out.
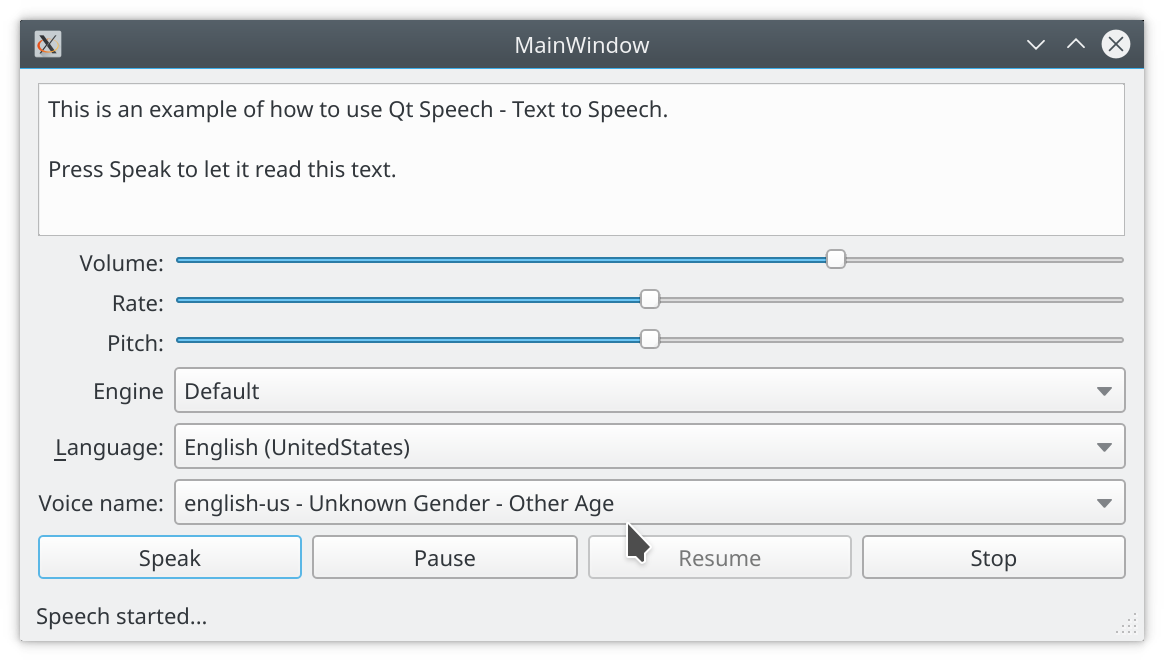
What's in the package? Text to speech, that's about it. The module is rather small, it abstracts away different platform backends to let you (or rather your apps) say smart things. In the screen shot you see that speech dispatcher on Linux does not care much about gender, that's platform dependent and we do our best to give you access to the different voices and information about them.
Making the common things as simple as possible with a clear API is the prime goal. How simple?
You can optionally select an engine (some platforms have several). Set a locale and voice, but by default, just create an instance of QTextToSpeech and connect a signal or two. Then call say().
m_speech = new QTextToSpeech(this);
connect(m_speech, &QTextToSpeech::stateChanged,
this, &Window::stateChanged);
m_speech->say("Hello World!");
And that's about it. Give it a spin. It's a tech preview, so if there's feedback that the API is incomplete or we got it all wrong, let us know so we can fix it ASAP. Here's the documentation.
I'd like to thank everyone who contributed, Maurice and Richard at The Qt Company, but especially our community contributors who were there from day one. Jeremy Whiting for general improvements and encouragement along the way (I bet he almost gave up on this project). Samuel Nevala and Michael Dippold did implement most of the Android backend, finally getting things into shape. Thanks!
You may wonder about future development of Qt Speech. There are some small issues in the Text to Speech part (saving voices and the current state in general should be easier, for example). When it comes to speech recognition, I realized that that's a big project, which deserves proper focus. There are many exciting things that can and should be done, currently I feel we need proper research of all the different options. From a simple command/picker mode to dictation, from offline options and native backends to the various cloud APIs. I'd rather end up with a good API that can wrap all of these in a way that makes sense (so probably a bunch of classes, but I don't have a clear picture in my mind yet) than rushing it. I hope we'll get there eventually, because it's certainly an area that is important and becoming more and more relevant, but I assume it will take some time until we have completed the offering.



