この記事は The Qt Blog の Optimizing the QML compiler pipeline を翻訳したものです。
執筆: Lars Knoll, 2018年05月22日
Qt QML は Qt Quick でユーザーインターフェースを構築する際のプログラミング言語である QML を実行するためのエンジンです。Qt QML 自体には描画機能に関する依存が一切ありません。このモジュールでは、QML 言語のサポートに加え、ECMAScript 5.1 に準拠した JavaScript のエンジンを提供しています。
Qt Quick というユーザーインターフェース技術の基礎を提供するこのモジュールは、Qt のユーザーに向けた核となるものです。内部的には主に2つの要素で構成されています。QML と ECMAScript をバイナリデータ構造とバイトコード/アセンブリにコンパイルするためのコンパイラパイプラインと、そこで生成されたコードを実行するためのランタイムです。今回の記事は前者についてのものになります。
5.10 まで利用していた Qt QML のコンパイラパイプラインはここ数年の Qt のアップデートでとても複雑になってしまいました。
以下の図は簡易化した以前のコンパイラパイプラインを示したものです。
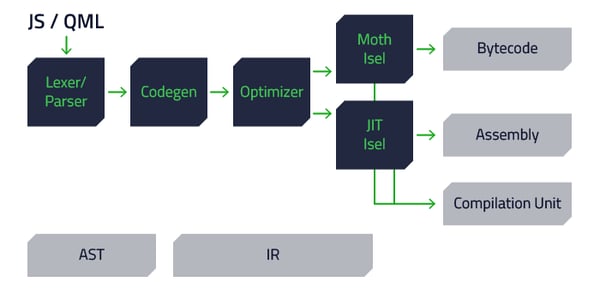
まず QML と JavaScript のコードを 字句解析器(Lexer) と 構文解析器(Parser) に送り、抽象構文木(AST) というコンパイル用のコードに変換します。この AST は Codegen と呼ばれるクラスに送られ、AST から 中間表現(IR) が生成されます。さらに、この IR は様々な最適化のステージを通過します。不必要なコードの削除やいくつかの型の確定、その他様々なトリックが用いられます。
次のステップでは、最適化された IR が2つある 命令選択(Isel) バックエンドのうちの1つに送られ、IR からバイトコードもしくはアセンブリ(とコンパイル単位に保持されるバイナリデータ)が生成されます。
これらはとても長くて複雑なパイプラインです。これによって QML/JS のコンパイルには必要以上に高いコストが発生し、アプリケーションの起動時間が遅くなっていました。さらに、バイトコードとアセンブリが別々になっていて、この2つをミックス/マッチさせる方法がありませんでした。
他の Javascript のエンジン(v8 や JavascriptCore)は、AST から直接バイトコードを生成して、それを JIT のために使うような別の形のパイプラインに移行しつつあります。このアプローチにはいくつかの利点があります。まず、QML/JS をプラットフォームに依存しない表現のバイトコード形式を得ることができます。バイトコードを生成するために QML/JS をパースする作業はとても軽い処理なので、起動時間は大幅に短縮されます。バイトコードに関するトレース情報はとても簡単に取得できるようになり、JIT コンパイラは完全に最適化したアセンブリを生成します。
昨年の夏に小さなリサーチセッションを開催し、Qt QML でも同じようなアプローチがとれないかを試してみました。たった2日間の作業でしたがこれは大成功で、コンパイラパイプラインを大幅に単純化することができました。
この結果を踏まえ、Qt 5.11 に向け、そのプロトタイプを元にした新しいパイプラインの実装をすることにしました。新しいパイプラインの概要は以下の図のようになります。
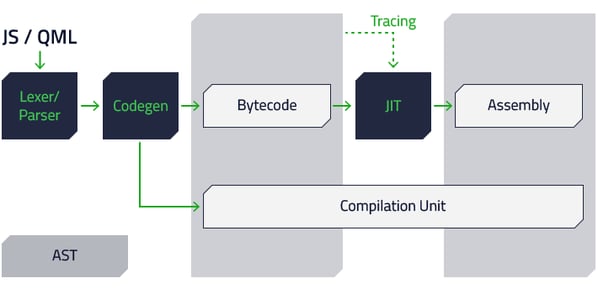
この新しいパイプラインでは、Codegen でバイトコードを直接生成し、すべての中間表現の利用をやめました。このバイトコードはプラットフォームに依存しないもので、直接実行可能な形式になっています。重要なコードパス(現在は頻繁に実行されている関数)は、JIT を利用してバイトコードをアセンブリにコンパイルしています。
同時に、バイトコード形式とそのインタープリタも刷新し、パフォーマンスを大幅に改善しました。ここでの目的は、RAM やディスクに保存可能なとてもコンパクトなバイトコードを生成することと、それに対する効率的で高速なインタプリタを実現することです。この結果にはとても満足していて、新しいインタプリタは以前のものに比べておよそ2倍高速に動作し、以前の JIT と比べて 80%〜90% のコストで動作するようになりました。バイトコードもとてもコンパクトで、以前の形式と比較すると膨大なメモリの消費量の削減を成し遂げました。それでは、実際に簡単な関数のバイトコードを見てみましょう。
function add(x, y) {
return x + y;
}
=== Bytecode for "add" strict mode false
1 0: 0a 06 LoadReg a2
2: 6a 05 Add a1, acc
4: 00 Ret
ご覧のとおり、生成されたバイトコードはわずか 5 バイトで、2つの引数をアキュムレーターにロードし、1つ目の引数を加算し、その結果を返しています。
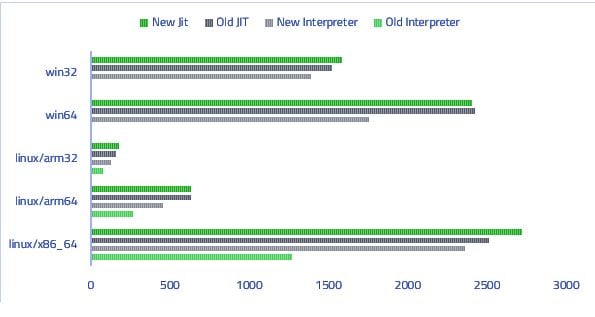
この新しいインタープリタの実装の後、頻繁に呼ばれる関数を最適化するための比較的シンプルなホットスポット JIT をそのインタプリタ上に追加しました。その JIT はまだトレース情報の利用やその他の最適化は行っていませんが、5.10 と比較するとパフォーマンスで優っています。以下のグラフは v8-bench というパフォーマンスのテストスイートを用いて改善の結果を可視化したものです(値が大きいほど良い)。New Interpreter/JIT が Qt 5.11 で刷新したもので、old は Qt 5.9 のものになります。
これらの改善により、QML のキャッシュ/ビルド時のコンパイル作業の作り直しが可能になりました。どちらも、今後はアセンブリではなく、新しい形式の コンパイル単位とバイトコードをディスクに保存するようになりました。これにより、バイナリサイズがとても小さくなり、起動時間が高速化されました。また、この高速な新しいインタープリタとホットスポット JIT の組み合わせは、以前の QML コンパイラと比較しても実行時のパフォーマンスが高くなっています。
これらの変更の副次的な結果として、これらすべてを統一化することに成功し、QML のコンパイラをオープンソースとしても公開することができました。このコンパイラを利用する際には注意点があり、バイナリコードの形式の互換性はバージョン間で保証していないため、パッチレベルまで完全に同一なバージョンの Qt が必要になります。自動的に生成される .qmlc/.jcs ファイルにはバージョンチェックの仕組みが含まれており、元となる .qml/.js ファイルの更新時や Qt のパッチレベルを含むバージョンの更新時に再生成されるようになっています。
今回のコンパイラパイプラインの単純化により、Qt 内部の様々なコードの整理整頓が可能になりました。JS/QML の関数実行時の呼出規約とスタックフレームの構築方法の設計を見直し、多くのオーバーヘッドを削減することができました。
この結果が分かる小さなベンチマークの例として、フィボナッチ行列を計算する関数の再帰実行があげられます。Qt 5.11 では以前のバージョンに比べ、3倍も高速化されました。
Qt 5.12 やそれ以降では、さらなる改善を計画しています。JIT のトレース情報の利用等に関するリサーチが現在進行中で、エンジンの ECMAScript 7 の完全サポートにも着手しています。ということで、今後のブログ記事もお楽しみに。